

 党建
党建


在中文语境中提到“AI审计( AI auditing )”,很容易等价于“用AI辅助审计”,为有所区别,本文将 AI auditing 翻译为 “AI风险审计”,文中如果提到“AI审计”也是指“AI风险审计”。
引言
随着AI、大模型不断落地,融入工作生产场景,风险也如影随形。
AI应用带来的风险包括功能失效、性能差异、法律不兼容、隐私保护、算法”黑箱“等问题,几乎影响到每一个使用场景,贯穿AI在实际应用中的方方面面。
从AI应用实践看,这些风险不仅涉及技术层面的问题,还包括社会、伦理和法律方面的考量。
AI审计(AI auditing)也日益需要提上议事日程,成为组织防范风险的重要组成部分。
Abeba Birhane、Ryan Steed、Victor Ojewale等5人对AI审计(AI auditing)进行了全面研究,发表了题为《 AI auditing: The Broken Bus on the Road to AI Accountability 》的研究报告(以下简称“研究报告”),对AI审计(AI auditing)的定义、方法、实践效果、存在的问题和展望等进行了详细研究。
《研究报告》不仅仅包括学术届对AI审计的研究,还包括新闻业、社会组织、政府、咨询机构和企业进行AI审计的实践案例和报告。
学术研究方面,收集分析了2018年至2022年期间发表的341篇研究论文,涉及跨学科计算和相关领域。
非学术领域,确定新闻业、社会组织、政府、咨询机构和企业,以及律师事务所等了几个主要行业,收集了这些行业关于AI审计的各种来源资料,包括网站上的信息、审计报告和其他相关文档。
这篇《研究报告》对全面了解AI审计的现状,从理论研究到实际应用的各个方面具有很高的参考价值。( 周末花了一天认真读完,颇有收获,分享之!)
另一方面,研究者用“Broken Bus”一词也形象地表明了当前AI审计存在诸多不足,面临很多挑战。
需要说明的是,《研究报告》收集的材料以英语为主,一定程度上不能覆盖全球的AI审计(AI auditing)情况。
AI审计的定义
《研究报告》将AI审计定义为:
An audit is defined as any independent assessment of an identified audit target via an evaluation of articulated expectations with the implicit or explicit objective of accountability.
一种独立于AI系统开发过程的评估机制,旨在对明确识别的审计目标进行客观考察,通过评估系统实际表现与明确或隐含期望之间的差距,以实现问责为核心目标。
这种评估涵盖了从自动决策系统到大型基础模型等多种AI部署,可应用于招聘、医疗、刑事司法等广泛领域,关注性能、安全、公平性等多个维度。
AI审计可在系统部署的不同阶段进行,采用定量或定性方法,旨在为相关利益相关者提供有意义的判断依据,潜在地影响系统的改进或应用决策。
这个定义意味着AI审计应该是由独立于AI系统开发团队的实体进行的,针对特定的AI系统或应用,基于预先设定的标准或期望,并以促进问责为最终目标。
AI审计的范围
《研究报告》指出AI审计可以涵盖非常广泛的目标,包括自动决策系统、在线平台或应用程序背后的推荐系统、计算机视觉中的大型基础模型、语音处理、基于文本的自然语言处理,或多模态模型。
AI审计范围的多样性反映了AI技术在各个领域的广泛应用,同时也突显了AI审计的复杂性。
AI审计可能需要针对不同类型的AI系统采用不同的方法和标准。例如,对自动决策系统的审计可能更关注公平性和透明度,而对推荐系统的审计可能更关注用户隐私和内容多样性。
AI审计分析框架
《研究报告》建立了一个三维度的分析框架,用于分析学术和非学术的审计源。
这个框架包括:
背景(Context):包括审计的动机、目标、审计对象、关注的危害类型以及审计可能如何改变利益相关者之间的权力关系; 方法(Methodology):包括调查目标工具的主要技术和程序; 影响(Impact):指审计直接导致的对目标工具、目标审计或机构环境的变化。
这个分析框架提供了一个全面的视角,允许研究者系统地比较和对比不同来源的审计实践,全面理解AI审计的复杂性和多样性。
通过考虑背景,研究者可以理解审计的动机和目标;通过分析方法,可以了解审计的具体执行方式;通过评估影响,可以判断审计的实际效果。
学术研究中的AI审计类型
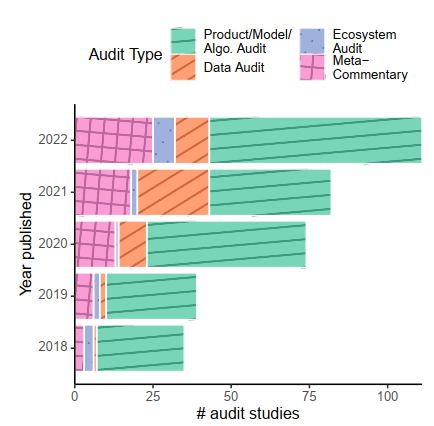
产品/模型/算法审计
产品/模型/算法审计( Product/model/algorithm audits )研究是学术界最常见的类型,主要针对具体的部署系统进行评估。研究对象包括社交媒体平台、公共服务算法、大型语言和视觉模型,以及搜索引擎等。
这些研究主要关注诊断失败、错误和差异。研究者发现,"bias"这个词在32.5%的摘要中出现,而"fairness"在21.2%的摘要中出现,反映了这类研究的主要关注点。
这类研究较少直接呼吁模型构建者和从业者进行相应的修改,研究更倾向于描述和分析问题,而不是直接推动变革。例如,"accountability"这个词只在14%的摘要中出现,这个比例低于生态系统审计(33.3%)和元评论(28.1%)。
数据审计
数据审计( Data audits )主要关注评估特定的数据集,通常是用于训练大型模型的数据集,有时也会审查用于模型评估的基准数据集。
这类研究更多地强调(无论是隐含的还是明确的)改变数据使用和基准测试实践的规范,而较少明确强调要求数据集创建者负责。研究发现,"accountability"一词只在9%的数据审计摘要中出现,而"bias"一词出现在39.1%的摘要中,这个比例高于其他任何类别。
数据审计使用的方法包括定量测量(如NSFW图像的发生率)、模拟、消融(removing或改变数据集的某些方面并测量结果)和critical assessment。这类审计通常由学术界、非营利组织和企业作者进行,主要检查开源和学术数据集。
生态系统审计
生态系统审计( Ecosystem audits )比其他类型的审计更多地关注公共服务,例如儿童福利机构使用的预测风险模型。这类研究的摘要中更频繁地提到特定领域,如招聘和教育。生态系统审计往往对危害和关切有更具体的定义,通常期望能对特定利益相关者甚至整个社会产生后续变化。例如,"accountability"一词在超过33%的生态系统审计摘要中出现,这是所有类别中最高的。
这些研究通常使用更广泛的方法,包括质性访谈、调查、工作坊和文献综述。考虑到调查范围,这些方法通常是全面和分散的,比更聚焦的审计调查less precise。例如,15个生态系统审计摘要中有6个提到了民族志、访谈、工作坊或其他定性方法,而有两个明确使用了"participatory"这个术语。
元评论与批评研究
元评论与批评类(Meta-commentary & critique)研究在AI审计领域扮演着重要角色。这类研究的摘要中有28.1%提到了"accountability",反映了它们对审计责任的关注。
使用的方法包括调查、访谈和文献综述,这些方法允许研究者对AI审计实践进行更广泛和深入的分析。这类研究主要由学术界、非营利组织或政府机构进行,例如NIST的AI风险管理框架。
研究的目标通常是发展方法论,许多研究将rigorous audit methods的开发视为重要贡献。这些研究提出的审计方法包括qualitative和quantitative approaches。
元评论研究还检查审计从业者本身,质疑算法评估和审计实践的规范。这类研究关注的危害往往less well-specified,大多提到某种形式的独立性、公平性、隐私或追索权。
特别值得注意的是critique studies,这类工作对审计作为一种实践进行反身性评论和批评。它们强调了一些结构性问题,如历史权力不平等可能被常见的学术审计实践所强化,或者审计如何可能成为企业责任的烟幕,如"audit washing"。
非学术领域的AI审计
《研究报告》对学术研究之外的AI审计样本进行了分析研究,这些样本来自于律师事务所、咨询机构和企业审计、新闻业、社会组织和政府,为全面评估AI审计实践提供了充分的素材。
《研究报告》特别关注非学术领域的机构背景如何影响审计实践和审计责任。每个领域都有其特有的专业知识、资源和目标,也在一定程度上说明AI审计实践的复杂性和适应性。
研究表明机构背景对审计实践有显著影响,不同领域的审计者在审计设计、开发和执行过程中采用的方法多种多样。例如,新闻机构可能更倾向于调查性报道和数据分析,而律师事务所可能更注重合规性和法律风险评估。
《研究报告》提供了一个表格(点击看大图),概述了不同审计主体在其所在审计领域的关键特征,如动机、目标、审计对象、方法和影响等,可以一目了然对不同领域审计实践的模式和差异进行比较。
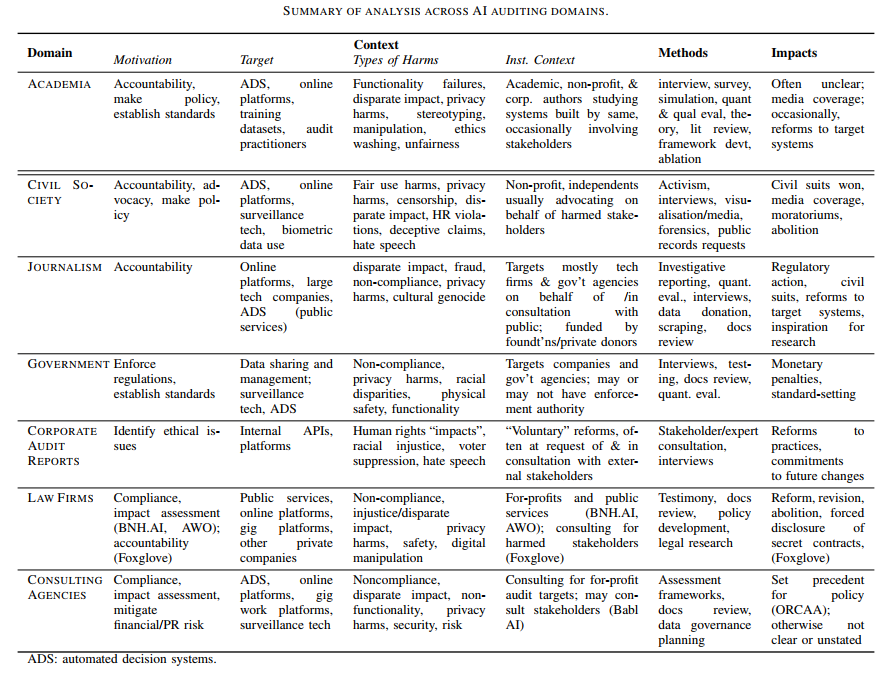
AI审计实践分析
《研究报告》用背景(Context)、方法(Methodology)、影响(Impact)的三维分析框架对律师事务所、咨询机构和企业审计、新闻业、社会组织和政府的AI审计实践分别进行了分析评价。
本文以政府部门的AI审计实践为例进行说明。
《研究报告》以两个政府组织:英国信息专员办公室(ICO)和美国国家标准与技术研究院(NIST)为例进行分析,可以看到不同国家和机构在AI审计方面的不同方法和重点。
背景(Context)
ICO进行审计的更广泛目标是维护信息权利并执行法律要求,NIST则主要关注建立标准和最佳实践原则,以确保社会负责任的算法系统的开发和部署。
ICO以个案为基础进行审计,通常以报告形式发布,而NIST倾向于对审计进行元评论。
ICO进行审计的核心目标主要是调查和执行法规,而NIST缺乏这种权威性,主要专注于建立标准。
方法(Methodology)
ICO和NIST采用了不同的审计方法,体现了监管机构和标准制定机构在AI审计中的不同角色和重点。
ICO开发了一套AI审计的框架,并设立了基于四个等级(高、合理、有限和非常有限保证)的评估合规性机制。
ICO进行审计的主要方法包括审查文件、测试和与关键人员进行访谈,通过审计全面评估组织的数据管理实践,并提供具体的改进建议。
相比之下,NIST的主要审计方法包括数据信任、准确性评估和基准测试,更侧重于技术标准和性能评估。
影响(Impact)
ICO和NIST的审计实践产生了不同类型的影响。
ICO作为监管机构,具有执法权,能够对违规行为进行处罚。ICO对数据保护法规违规行为开出了罚单,包括对TikTok滥用儿童数据罚款1270万英镑,对Clearview AI公司罚款1700万英镑。此外,ICO还发布了停止进一步处理英国人个人数据的通知,并要求删除这些数据。
而NIST则是通过其AI风险管理框架(RMF)在美国监管对话中产生了重大影响。NIST没有执行指南的权力,但通过塑造行业标准和最佳实践进行指导和引导。
完善AI审计的思考
《研究报告》指出在确定审计影响力时,最有影响的因素之一是审计者如何与各种利益相关者(包括受影响的人群、审计目标和其他方)互动的权力分析。如果不考虑结构性因素(如权力、控制、利益和危害的不均衡分布),仅仅进行方法创新和AI系统评估不太可能产生重大影响。
《研究报告》建议,未来的研究应进一步探索工具和策略,以映射、定义和培养审计者与各种利益相关者的关系。同时,政策制定者和其他权威机构可以采取措施赋予审计者权力,例如将审计结果纳入对公司的更具后果性的惩罚中,或者开源、发布、传播和审查提交的审计结果。
超越产品、模型或算法
《研究报告》使用"生态系统审计"分类来描述那些全面考虑整个AI流程的研究,包括定义或受AI系统关键组件影响的社区和社会技术环境(数字或物理)。虽然这些生态系统审计体现了各种学术批评中倡导的社会技术审计的许多元素,但大多数学术审计研究极少涉及对相关利益相关者的全面分析,也很少全面审视多个相互作用的AI系统。
《研究报告》建议,未来的工作应继续纳入和扩展更广泛的视角,以便对算法系统及其影响形成更丰富的描述,考虑AI系统在更广泛的社会和技术背景中的作用和影响。
《研究报告》还指出AI审计目标的选择、明确的动机、调查的危害类型以及审计目标的范围等结构性细节,比审计执行的细节更可能决定审计结果的有效性。
《研究报告》从8个方面对完善AI审计进行了讨论,主要方面如下:
具体化提升有效性
《研究报告》指出,即使审计研究扩大了范围以包括围绕和定义AI系统的生态系统,大多数审计仍需要更加具体才能产生更大影响。当审计范围过于分散时,审计有效性不高。
《研究报告》建议,未来的工作应该在不失去对整体的聚焦和生态观察同时,力求高度具体。
采用更广泛的审计方法
《研究报告》发现,在计算机科学和相关学术场合,定量方法常常处于AI审计的中心地位。这些方法体现在这些社区开发和讨论的各种公平性指标中。研究者指出,这些方法有很大的局限性,包括其抽象性、法律不兼容性以及与实质性结果缺乏联系。
而在许多非学术领域,所采用的方法远远超出了学术界正在探索或常讨论的范围,包括一系列定性方法,如调查性报道、文件审查和利益相关者咨询。
时机和审计者类型
《研究报告》指出,关于审计应该在何时进行(即事前、过程中、事后)的区分最近成为一些政策辩论的主题。如预期的那样,那些拥有更多访问权限的人(即内部审计者)有机会在部署前执行审计,而其他人(即外部审计者)被限制在部署后进行审计。然而,当涉及将审计结果转化为审计责任时,这两种情况都面临着挑战,其他如目标、设计、沟通和范围,最终可能更有意义。
例如,尽管内部审计人员可以更早和更深入地访问,但他们可能仍然难以说服关键人根据审计结果采取行动。内部审计人员可能容易受到内部企业报复和企业审查的影响,以及陷入利益冲突。
另一方面,外部审计人员可以自由设置其范围并公开传达结果。然而,他们面临着外部合法性和可见性的问题,他们在审计能力和信息访问方面面临的困难进一步阻碍了审计质量。
认识审计的限制
《研究报告》指出,AI的某些社会影响不适合审计。由于AI产生的一些的危害 - 例如,监视的寒蝉效应,或公司权力集中,不是所有关于技术的问题都可以通过审计来解决。
《研究报告》强调需要多方面、多角度地评估AI系统的社会影响问题,而不是过度依赖任何单一的评估或责任机制。
审计方法多样性
《研究报告》强调,在许多非学术领域,所采用的方法远高于学术界正在探索或讨论的内容,包括一系列定性方法方法,如调查性报道、文件审查和利益相关者咨询。
《研究报告》认为不同的方法可能适合不同的审计目标和背景,建议未来的工作中,AI审计研究应该探索这些学科外的方法和策略,如何能够增强学术审计工作,尤其是那些具有经验证过的影响记录的方法。
(Claude对观点提炼亦有贡献)
原文标题:《研究 | 任重道远:一文全览AI风险审计的定义、方法、实践和展望》



 97046009
97046009

